Paper
Query Rewriting for Retrieval-Augmented Large Language Model
0 Abstract
- RAG LLM을 위해 새로운 프레임워크인
Rewrite-Retrieval-Read가 제안된다. - 리트리버 또는 리더기 중 하나를 적응시키는데 초점을 맞춘 이전 연구와 달리 이 접근 방식은 검색 쿼리 자체의 적응에 집중한다.
- 파이프라인에 대해 학습 가능한 체계가 제안되며, 여기서 블랙박스LLM 판독기를 충족시키기 위해 학습 가능한 재작성기로 Small Language Model이 채택되었다.
- Rewriter는 강화학습에 의해 LLM 판독기의 피드백을 사용하여 훈련된다.
- 다운스트립 작업에 대한 실험은 일관된 성능 향상을 보여주며, 이는 프레임워크의 효율성과 확장성을 나타낸다.
1 Introduction
- LLM은 few-shot or zero-shot에서 인간의 언어 처리 및 확장성에 탁월한 능력을 보여주었다.
- 그러나 LLM은 할루시네이션과 temporary misalignment와 같은 문제에 직면하여 신뢰성과 실제 적용에 영향을 미쳤다.
- 외부 지식과 내부 지식을 통합하면, 특히 지식 집약적인 작업에서 환각을 완화할 수 있다.
- RAG LLM은 LLM 세대에서 사실성을 증명하는데 효과적이었다.
- 검색 증강은 Retrieve-then-read 프레임워크에 따라 언어 모델의 외부 컨텍스트로 관련 구절을 선택한다.
- Open Domain QA에서, 리트리버는 질문에 대해 관련 문서를 검색하고, LLM은 질문과 문서를 기반으로 답변을 예측한다.
- 대부분의 LLM은 추론 API를 통해서만 액세스 할 수 있기 때문에 파이프라인에서 블랙박스 Frozen LLM 역할을 한다.
- (확인할 수 없다.)
- 최근 연구로는
- LLM의 피드백을 사용하여 LLM 입력 컨텍스트를 최적화하도록 dense retreval model을 훈련하는 것
- 리트리버와 Reader사이의 상호 작용을 설계하여에 초점을 맞추고 있는데, 종종 정지된 상태이며, 조작된 프롬프트 또는 정교한 프롬프트 파이프라인을 통해 능력을 이끌어 낸다.
- 외부 지식과의 여러 상호 작용을 통해 LLM은 정답에 점진적으로 접근한다.
- 그러나 기존 접근 방법은 쿼리의 적응을 관과하고 있다.
- 검색 쿼리는 데이터 세트에서 원본이거나 블랙박스 생성에 의해 직접 결정되므로 항상 고정이다.
- 그러나 입력 텍스트와 실제로 쿼리르하는데 필요한 지식 사이에는 필연적으로 격차가 잇다.
- 이는 성능을 제한하고 검색능력 향상 및 신속한 엔지니어링에 부담을 준다.
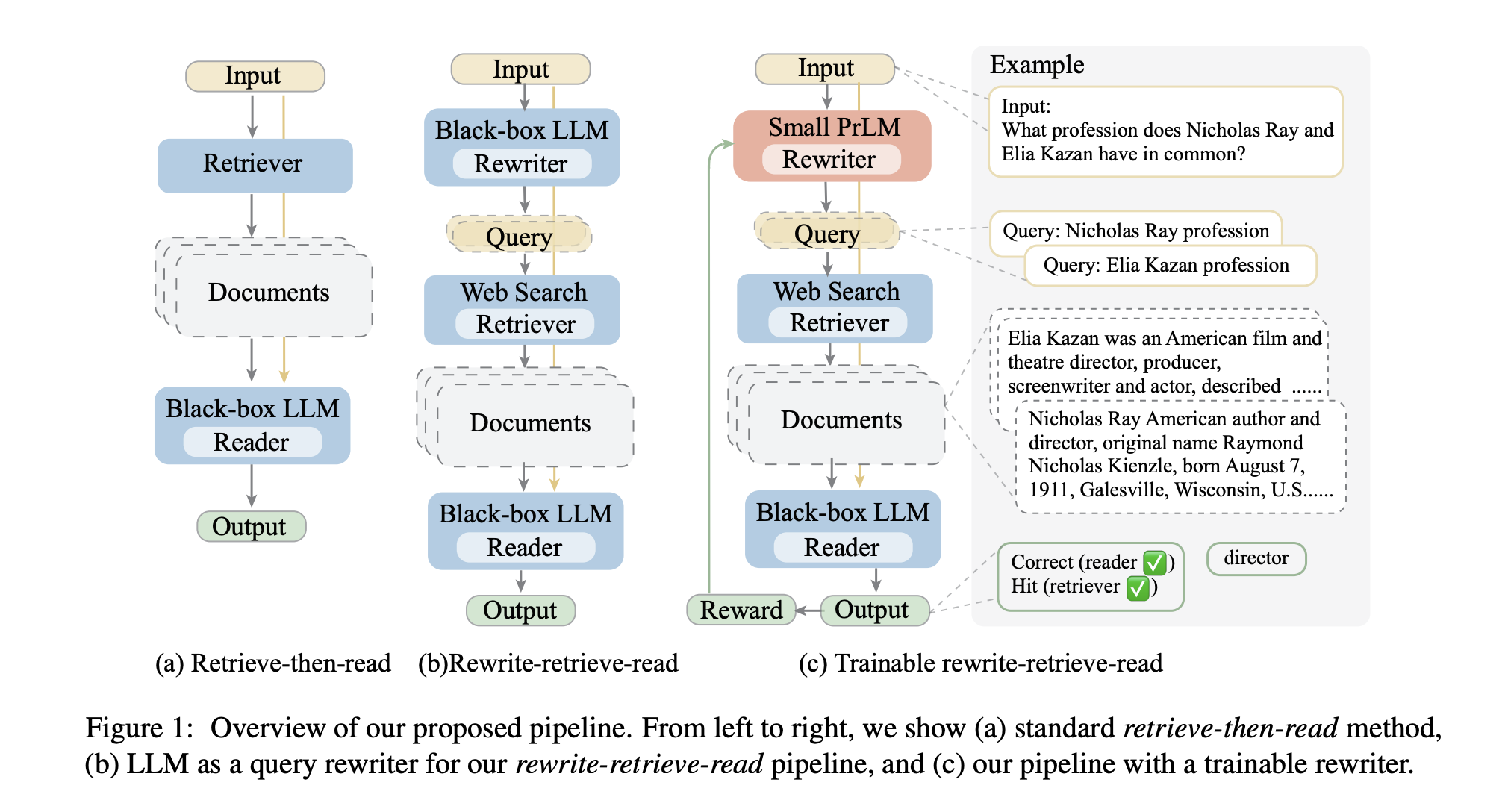
- 본 논문에서는 LLM에 적응 가능한 RAG의 새로운 프레임워크인
Rewrite-Retrieve-Read를 제안한다. 입력과 검색 요구 사이의 격차를 해소하기 위해 리트리버 이전에 다시 쓰기 단계를 추가한다.- 이 프레임워크는 기성 인터넷 검색 엔진을 리트리버로 활용하여 검색 인덱스를 유지 관리할 필요가 없으며 최신 지식에 대한 액세스를 가능하게한다.
- 리트리버와 LLM 간의 여러 상호작용 라운드에 대한 기억이 필요한 기존 연구와 달리, 이 재작성 단계는 입력 텍스트에서 검색 요구를 명확히 하는 것을 목표로한다.
- 제안된 방법은 Open Domain QA, AmbigNQ, PopQA 및 multiple choice QA를 포함한 지식 집약적인 다운스트림 작업에서 평가된다.
- 실험은 재작성자인 T5-large, ChatGPT와 LLM 판독기인 Vicuna-13B에서 구현된다.
- 결과는 쿼리 재작성이 일관되게 검색 증강 LLM 성능을 향상시킨다는 것을 보여준다.
- 결과는 또한 더 작은 언어 모델이 쿼리 재작성에 적합할 수 있음을 나타낸다.
- 요약하면 제안된 새로운 검색 증강 방법인
Rewrite-Retrieve-Read는 입력 텍스트가 frozen retrieval 및 LLM 판독기를 위해 조정된 첫 번째 프레임워크이다. 더 적은 자원 소비로 성능 향상을 달성하는 작고 훈련 가능한 모델을 사용하여 조정가능한 계획을 도입한다.
2 Related work
2.1 Retrieval Augmentation
- 언어 모델은 사실적 한계를 해결하기 위해 외부 지식으로부터 정보를 얻는다.
- 검색 모듈을 사용하여 관련 정보를 컨텍스트로 제공하는 Retrieveal module은 효과적인 것으로 입증되었다.
- 이전 연구에서는 사전 학습된 언어 모델과 함께 희소하거나 밀도가 높은 검색기를 사용했다.
- 전체
retrieve-then-reader프레임워크는 조정 가능한 E2E 시스템이며, 검색된 컨텍스트는 중간 결과로 사용된다. - 2단계 프로세스를 원할하게 하기 위한 접근 방식은 검색 및 읽기 이해를 최적화하는 것을 목표로 한다.
- 모델 및 데이터 크기가 빠르게 증가함에 따라 검색은 여전히 강력한 개선 사항으로 남아있다.
- 아틀라스에 의해 입증된 바와 같이
retrieval와reader의 공동 훈련은 크기가 상당히 작으면서도 대형 모델에 필적하는 성능을 달성할 수 있다.
The Internet as a knowledge base
- 검색엔진은 인터넷에서 정보를 검색하고 지식의 원천 역할을 할 수 있다.
- 최근의 연구들은 대화 응답 생성, 지식 추출, 팩트체크 등 다양한 작업에 웹 검색을 활용하는 효과를 보여주고 있다.
- Komeili 및 SeeKeR은 대화 응답 생성을 위해 인터넷 검색을 사용한다.
- 웹 검색은 지식 증강, 팩트 체크 및 LLM 에이전트 강화에 효과적이다.
2.2 Cooperation with Black-box LLMs
- LLM은 인상적인 자연어 처리 능력과 확장성을 보여줌으로써 NLP 작업에 널리 채택되고 있다.
- 그러나 대부분의 LLM은 폐쇄 소스 특성 또는 계산 리소스 요구 사항으로 인해 블랙박스로만 접근할 수 있다.
- 기존 연구들은 신중하게 설계된 상호작용 방법이 LLM의 기능을 향상시킬 수 있음을 입증했다. LLM의 내부 지식을 활용하고, 웹 API 상호작용에 CoT(Chain-of-Thought)를 결합하며, LLM과 리트리버 사이의 파이프라인을 구축하기 위해 GenRead, ReAct, Self-Ask 및 Delimate-Search_Predict(DPS)와 같은 기술이 개발되었다.
- LLM의 동작을 조정하기 위한 실현 가능한 접근법은 LLM 전후에 훈련 가능한 소형 모델을 추가하는 것이다.
- RePlug는
retrieve-then-read파이프라인에서 frozen LLM을 위한 고밀도 리트리버를 미세 조정합니다. - Directional Simulus Prompts는 LLM에 자극을 제공하기 위해 작은 모델을 사용한다.
- 제안된 파이프라인에는
retrieve-then-read모듈 전에 쿼리 재작성 단계가 포함되어 있다. - 검색 쿼리를 재구성하여 검색 증강 LLM을 위한 새로운 향상된 작은 재작성 모델을 가진 훈련 가능한 체계를 제안한다.
3 Methodology
- 쿼리 재작성 관점에서 검색 증강 LLM을 개선하는 파이프라인인
Rewrite-Retrieve-Read를 제시한다. 이 섹션에서는 먼저 섹션3.1에서 파이프라인 프레임워크를 소개한 후 섹션 3.2에서 훈련 가능한 계획을 소개한다.
3.1 Rewrite-Retrieve-Read
- 검색 증강을 갖는 태스크는 쿼리를 생성하고, 관련 컨텍스트를 검색하고, 컨텍스트로 입력을 이해하고, 출력을 예측하는 것을 포함한다.
- 질의를 생성하기 위해, LLM이 퓨샷 프롬프트와 함께 사용되어 잠재적으로 필요한 정보를 검색하기 위해 하나 이상의 질의를 생각하고 출력하도록 장려한다.
3.2 Trainable Scheme
- Frozen LLM에 대한 전체 의존도는 추론 오류 및 잘못된 검색과 같은 단점이 있는 반면, (잘못) 검색된 지식은 언어 모델을 오도하고 손상시킬 수 있다.
- Frozen 모듈과 더 잘 정렬하기 위해 LLM 판독기 피드백을 보상으로 받아 학습 가능한 모델을 추가하고 조정하고자한다.
- 프레임워크는 재작성 단계를 인수하기 위해 훈련 가능한 작은 언어 모델을 활용할 것을 제안한다.
- 훈련 가능한 모델은 사전 훈련된 T5-Large로 initial되고 강화 학습에 의해 지속적으로 훈련된다.
3.2.1 Rewriter Warm-up
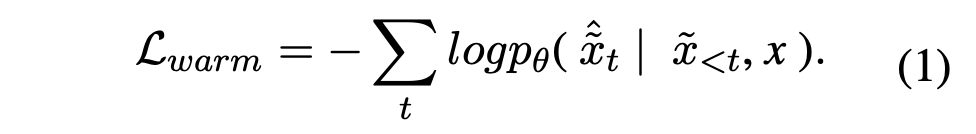
- 질의 재작성은 T5와 같은 sec2sec 생성 모델의 사전 훈련 목적과는 다르다. pseudo 데이터셋는 LLM에게 원본 질의를 재작성하도록 요청하고 생성된 질의를 pseudo 레이블로 수집함으로써 구성된다.
- 수집된 샘플들은 필터링되고, LLM 판독기로부터의 정확한 예측들을 갖는 샘플들은 웜업 데이터셋트 내로 선택된다.
- 재작성 모델은 표준 로그 가능성을 훈련 목표로 하여 웜업 데이터 세트에서 미세 조정된다.
- 워밍업 후 리라이터 모델은 pseudo 데이터 품질과 리라이터 능력에 따라 약간의 성능 향상을 보여준다.
- 인간이 작성한 프롬프트 라인에 크게 의존하기 때문에 x는 최적이 아닐 수 있다.
- 상대적으로 리라이터 크기의 규모가 작은 것도 워밍업 이후 성능의 한계이다. 그렇기 때문에 리트리버와 LLM 리더에 재작성기를 정렬하기 위해 강화 학습으로 전환한다.
이후 내용은 다음 논문을 읽은 후에 작성한다.
Proximal Policy Optimization (PPO) (Schulman et al., 2017)

댓글